{kind=link}
Safeguarding AI: Centralized Guardrails for Generative AI Gateways
As companies increasingly turn to generative AI to streamline their processes and boost employee productivity, the need for robust safeguards and compliance measures becomes evident. Automating workflows using AI agents and chat-based assistants carries significant implications, especially when handling sensitive data. Implementing comprehensive auditing controls and responsible AI practices is essential for any enterprise relying on large language models (LLMs). This article explores how organizations can integrate centralized guardrails in a multi-provider generative AI gateway to enhance safety while utilizing Amazon Bedrock Guardrails.
Evolutive Needs of AI in Enterprises
The growing reliance on large language models (LLMs) for automation has led many organizations to deploy either custom generative AI gateways or utilize off-the-shelf solutions like LiteLLM or Kong AI Gateway. These environments provide developers with access to various LLMs, including those from providers like Amazon and Microsoft Azure. However, a prominent challenge remains: policymakers must enforce consistent guidelines for ensuring prompt safety and protecting sensitive data across multiple AI service providers.
Centralized Safeguards Overview
To effectively safeguard generative AI applications, organizations must establish a comprehensive framework that incorporates several key requirements. First and foremost is a scalable infrastructure that supports both the generative AI gateway and its guardrails components. This includes a sophisticated logging and monitoring system capable of tracking AI interactions while analyzing usage patterns for compliance purposes.
Establishing clear data governance policies is key to ensuring sensitive data protection. Furthermore, a chargeback mechanism is crucial for tracking AI usage costs across departments or projects. Lastly, organizations must remain cognizant of industry-specific regulatory requirements, ensuring that their guardrails align with these standards.
The Workflow in Action
Imagine a scenario where authenticated users submit HTTPS requests to the generative AI gateway hosted on Amazon Elastic Container Service (ECS). Each request is directed to the Amazon Bedrock ApplyGuardrail API, responsible for content screening. Depending on predefined configurations, requests are either blocked, deployed with masked sensitive information, or allowed to pass unaltered.
This evaluation is a fundamental aspect of adhering to established safety guidelines. Once cleared, the request is forwarded to the appropriate LLM provider based on user specifications. The response is then retrieved, ensuring that the user receives either a notification of the blockage or the processed content with any necessary masking.
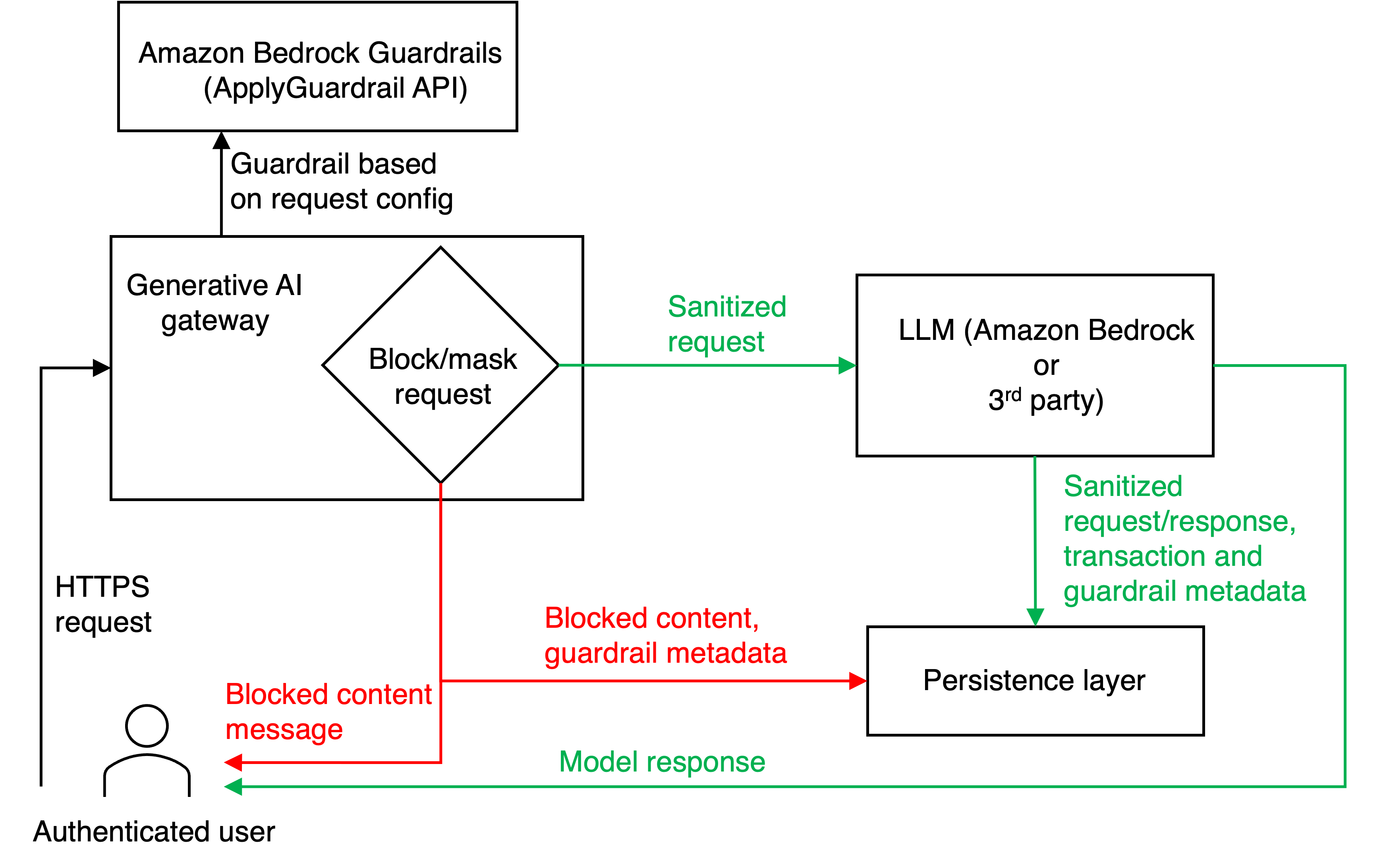
In essence, this approach standardizes security and compliance for both Amazon Bedrock and third-party providers while allowing organizations to manage AI interactions seamlessly.
Key Components of the Solution
To achieve scalability and effective security, the following tools and technologies are integrated into the solution:
- nginx: Enhances performance and stability by load balancing requests among containers.
- Gunicorn: A high-performance WSGI HTTP server that efficiently manages concurrent requests.
- Uvicorn: Provides asynchronous request handling, essential for applications with longer wait times.
- FastAPI: Manages requests at the generative AI gateway layer.
- Amazon ECS Fargate Cluster: Hosts the containerized application with automatic resource scaling.
- Amazon ECR: Stores Docker images of the generative AI gateway application.
- AWS Auto Scaling: Adjusts the number of active tasks or containers based on demand.
- HashiCorp Terraform: Facilitates infrastructure provisioning.
Architecture Design
The overall architecture is designed to facilitate several consumer applications, dashboards, and Azure Cloud components. The generative AI gateway efficiently connects these different environments, serving as the interface for user interactions.
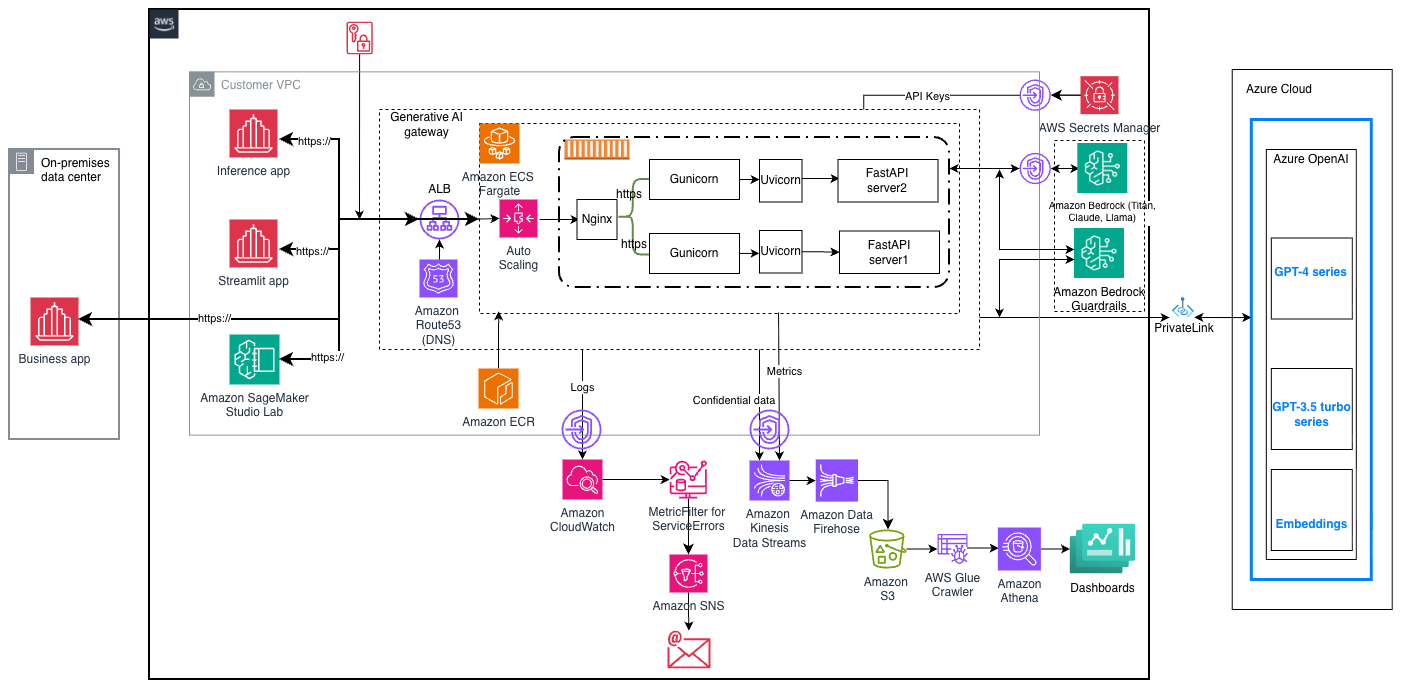
Implementing Centralized Guardrails
Amazon Bedrock Guardrails play a crucial role in enforcing security through the ApplyGuardrail API, which introduces several core safety features:
- Content Filtering: Screens requests for harmful or inappropriate content.
- Denied Topics: Blocks discussions on sensitive subjects.
- Word Filters: Restricts the use of specific terms or phrases.
- Sensitive Information Detection: Protects personally identifiable information (PII).
These guardrails can be configured to various strength levels—low, medium, or high—allowing different business units to tailor the security posture according to their specific risk tolerances. For instance, marketing teams might favor less restrictive guidelines for content creation, while healthcare or financial divisions could demand stricter measures for handling client data.
Beyond these foundational features, Amazon Bedrock Guardrails also introduces advanced capabilities like contextual grounding and automated reasoning checks to minimize instances of AI hallucinations—when the model generates misleading information.
Flexibility with Multi-Provider Integration
A key advantage of the generative AI gateway is its compatibility with multiple LLM providers and models. Users seamlessly specify their desired LLM model in the request, enabling the gateway to route requests accordingly. AWS Secrets Manager secures API access tokens, ensuring safe communication with third-party providers like Azure OpenAI.
Automated Logging and Monitoring
Centralized logging and monitoring form the backbone of this generative AI gateway. Every interaction—be it user requests, LLM responses, or any contextual details—is systematically captured. This systematic approach not only aids in troubleshooting and analyses but also plays a pivotal role in ensuring compliance and optimizing application performance.
Tools for Logging and Monitoring
The solution employs various AWS services for structured logging and monitoring:
- Amazon CloudWatch: Captures container and application logs, allowing for custom metrics and proactive alerts.
- Amazon SNS: Ensures timely notifications for critical system errors.
- Amazon Kinesis: Streams requests and responses for compliance and analytics.
- Amazon S3: Stores transaction metadata securely for record-keeping.
- AWS Glue and Amazon Athena: Streamlines ETL operations and provides a SQL interface for data insights and analytics.
Repository Structure
Developers can utilize the provided GitHub repository to explore the architecture, defined directory structures, and code related to the application.
bash
genai-gateway/
├── src/
│ └── clients/
│ ├── controllers/
│ ├── generators/
│ ├── persistence/
│ └── utils/
├── terraform/
├── tests/
│ └── regressiontests/
├── .gitignore
├── .env.example
├── Dockerfile
├── ngnix.conf
├── asgi.py
├── docker-entrypoint.sh
├── requirements.txt
└── README.md
Prerequisites for Deployment
To deploy this solution, organizations need to meet certain requirements, including access to AWS and the necessary IAM roles for various AWS services such as Amazon S3, CloudWatch, and Bedrock.
Deploying the Solution
Deployment is facilitated through simple scripts:
- Clone the repository.
- Execute
deploy.shto set up the infrastructure. - Verify the environment using
verify.sh. - Generate consumer authorization tokens.
- Test the generative AI gateway according to the provided instructions.
Examples in Action
Consider a scenario illustrating how the generative AI gateway enforces guardrails against denied topics. By using a structured curl command, users can command the API to handle financial inquiries, allowing the implemented guardrails to respond if questions diverge from acceptable topics.
bash
curl -k -X POST “$URL” \
-H “Content-Type: application/json” \
-H “appid: $APPID” \
-H “apitoken: $APITOKEN” \
-d ‘{
“requestid”: “1”,
“requestdatetime”: “2025-10-27T15:51:47+0000”,
“appid”: “admin”,
…
}’
Similarly, testing the gateway’s ability to shield personal information demonstrates its effectiveness in masking PII before processing requests.
Cost Considerations
When deploying such a solution, organizations should be mindful of cost implications across various services, including LLM provider fees, AWS infrastructure costs, and expenses associated with Amazon Bedrock Guardrails.
Continuous Improvement with Feedback Loops
Implementing centralized guardrails equips organizations to make significant strides in adopting generative AI while adhering to compliance and safety standards. Through systematic logging, monitoring, and adaptive security configurations, enterprises can safely unravel the transformative potential of AI across various use cases and industries.
By employing a multi-provider generative AI setup, businesses can stay agile and innovative while navigating the complexities of regulatory environments, ultimately securing the trust of their clients and stakeholders.